

I had an amazing time this weekend being a mentor at Athena Hacks, an all girls hackathon held in Southern California. It was really amazing to help a handful of the 400 participants work on their projects and trouble shoot any issues they ran along the way.
2nd Place: Hack IOT

Me with the judges of HACK IOT
I spent this weekend at HACK IOT, the West Coast's first IoT-specific hackathon, working on some really cool technology with my teammate Kaushal Saraf.
Inspiration
The really amazing thing about HACK IOT is the huge amount of resources they have available to the teams. From raspberry pis to routers to even a handful of 3D printers for team to use. When trying to use some of these resources however I ran into a major problem - all of these devices used USB 3.0 but my MacBook Pro only had USB C.
The effort to move to a single port in USB C has meant that a lot of devices are a little bit antiquated in terms of their IO interfaces. This means that for the 40 million usb 3.0 devices that are still sold each month, the only way for them to be used by people with only USB C is through the dreaded dongle.

What we Built
Now there’s a fundamental problem with dongles: no one has them when you need them. So in order to better address the huge transition from USB 3.0 to USB C my team built a solution that doesn’t require actual hardware to interface with a USB 3.0.

Essentially what our team built was a wireless usb stick using a raspberry pi zero . Now we can use any USB device like it was a wireless device without the need for dongles. In the process of making the device - I learned way more about USB and the differences between 1.0 2.0 and 3.0 than anyone should ever have to learn.
In order to hook this device to any USB only device, just plug it into the USB port. That’s all! The device we made automatically makes anything it is plugged into effectively wireless.
Real World Example
A really great example of this is the printer I use in college. Since its super old printer that only takes in a usb stick as an input almost no one can use it (more than half the people who use it have USB C on their computer). As a result there’s been a lot of talk around this printer, which works perfectly well, being replaced in the near future for no reason other than the fact that most people can’t use USB 3.0 to connect to the printer anymore.
The 5 dollar solution my team built this weekend effectively removes the friction point for users who want to see this printer replaced, and future proofs this device so its useful life isn’t cut short arbitrarily. I plugged in the prototype my team built into the printer’s USB 3.0 port today morning, let’s see what people think of my solution in practice and whether we can save the environment a little bit by not replacing this working printer.
Spring Break 2019: Yosemite




Preparing for the Camino de Santiago

My group of friends who I am walking the Camino de Santiago with in Spain this summer
How do you prepare to walk 200 miles across Portugal and Spain? Lots and lots of practice. But I’m looking forward to my trip this summer!
Marshall International Case Competition Challenger

The dream team from left to right: Abhishek Aggarwal, Joel Joseph, Rehan Haider, and Emilio Setiadarma
This weekend I had the amazing experience of working with an amazing team to compete in the Marshall International Case Competition Challenger. Now despite the fact I was the one of the only non business students competing this weekend, I didn’t let that deter me. If anything it was able to complement the finance heavy nature of the team, with the other 3 members strong financials background complementing my experience pitching startups in the past. Not only could I craft a compelling and logical story about the expansion, but my teams could create the finance projections to back it up.
The business case we worked on this weekend revolved around a company name True Fruits, which brought the smoothie to Germany. Essentially when they started no one in Europe knew what a smoothie was, yet today they are the biggest player in smoothies. The question we were asked to present on was whether it was time to expand internationally, and if so what the ideal markets would be to expand into.
To see the exact case click me.
Now just as important as the final result is the way my team came about our recommendations. Very early on our team’s strategy revolved finding the core question, which in this case was if and how True Fruits should expand its market internationally, and building a story around it. In order to build that story I structured the major questions in the case almost
We first started off with why now was the right reason for the company to expand. Much like how this company picks its fruit at the ripest point, the European Smoothie Market was ripe for the picking. This explained why expansion was necessary.

We then moved on to our analysis of neighboring European countries, and explained why we thought that France, Italy, and Spain were the ideal markets to enter. This explained where the company needed to expand.

We finally ended up on how the company should expand. We believed that the expansion should happen in the core smoothie business as opposed to any of their other juice and fruit products. The reason being is strategically, smoothies are a defendable business. Juices and fruit products have long shelf lives, meaning if a Starbucks or international player wanted to win marketshare overnight they could do it by pouring in money. But the smoothies have a shelf life of a maximum of a week, meaning they need to be produced somewhat locally, giving the business a natural moat against any future challengers.
Moreover my team believed that a staggered expansion was the best, given the fact the company had only 20 employees. The idea was that the company should spend the first year testing out the markets by exporting directly from their German facilities. If the market developed and they had good traction (we had specific numbers we presented to the judges), then we would build local production in that market. If not, we would just continue exporting until the market developed. The core of the strategy was to build optionality, and not overextend the company as the companies culture was steady but solid expansion overtime.
Another thing to note is that this company’s marketing strategy of crude humor in the German market, while effective domestically, would not be appreciated in other countries. In fact many times the marketing campaigns the company put out were frankly sexist and racist. As a result our team realized that not only would be ethically bad to expand these marketing strategies internationally, but it also wouldn’t be the best thing for the company’s bottom line. The way our team mitigated this problem was by suggesting that all marketing for the company in international markets be handled by local advertising firms. This helped make the marketing more tailored to each country.
Moreover we included some partners for the launch. We focused on finding the European equivalent of Whole Foods in each of the markets to sell the smoothies, while also finding a local high end gym to help market our product at least initially. This explained how the company would expand.

Our team thought the background was pretty funny. This was an image we stole from the company website of a woman doing a “line of smoothies.” We thought it fit in because we were presenting a timeline of smoothies.
























SCheduler Part 2

My amazing team for the SCheduler project!
This is Part 2 of a Project I worked on this semester. To see Part 1 Click Me
This semester a couple friends and I built a Web Application that helps student schedule their classes. Each student at USC on average takes about 5 different classes which have up to 5 different meeting times each week. When you factor in all the times a class might be offered coupled with all the different permutations of classes you can take in a semester, most students are left with dozens of different schedules to choose from.
Our Web Application makes it extremely simple to know what your options are for the next semester.

The landing page of our Web Application

Step 1: Enter the 5 courses you want to take next semester into the system.

Step 2: See all the different schedules you can take.
If you look back to my earlier post on SCheduler I explained a little bit of the Web Scraping I did off USC’s website. Essentially I scraped class information from USC and populated it into a FireBase cloud-store database, where our web application could access it.
To check out my team’s presentation click me !!!
Now because our team was relatively new to building Web Applications we had to learn some new technologies off the bat like : Flexbox, Maven, JGraphT, FireBase.
Cool Extras:
1) Login Functionalities - Using Google Login. This allows users to save schedules that they like in case they want to come back later.
2) Search Capability - By typing in your friend’s name, you can see any schedules he or she has saved which is perfect if you want to take classes with them
3) Multithreaded Notifications - Every time someone creates a schedule using the platform every user on the platform is notified. Behind the scenes this required the use of server sockets which added another layer of skill building to this project.
I really enjoyed working on this project with my team! It was really fun building something that I actually used to make my class schedule for the upcoming Spring.
Mentoring @ Hour of Code
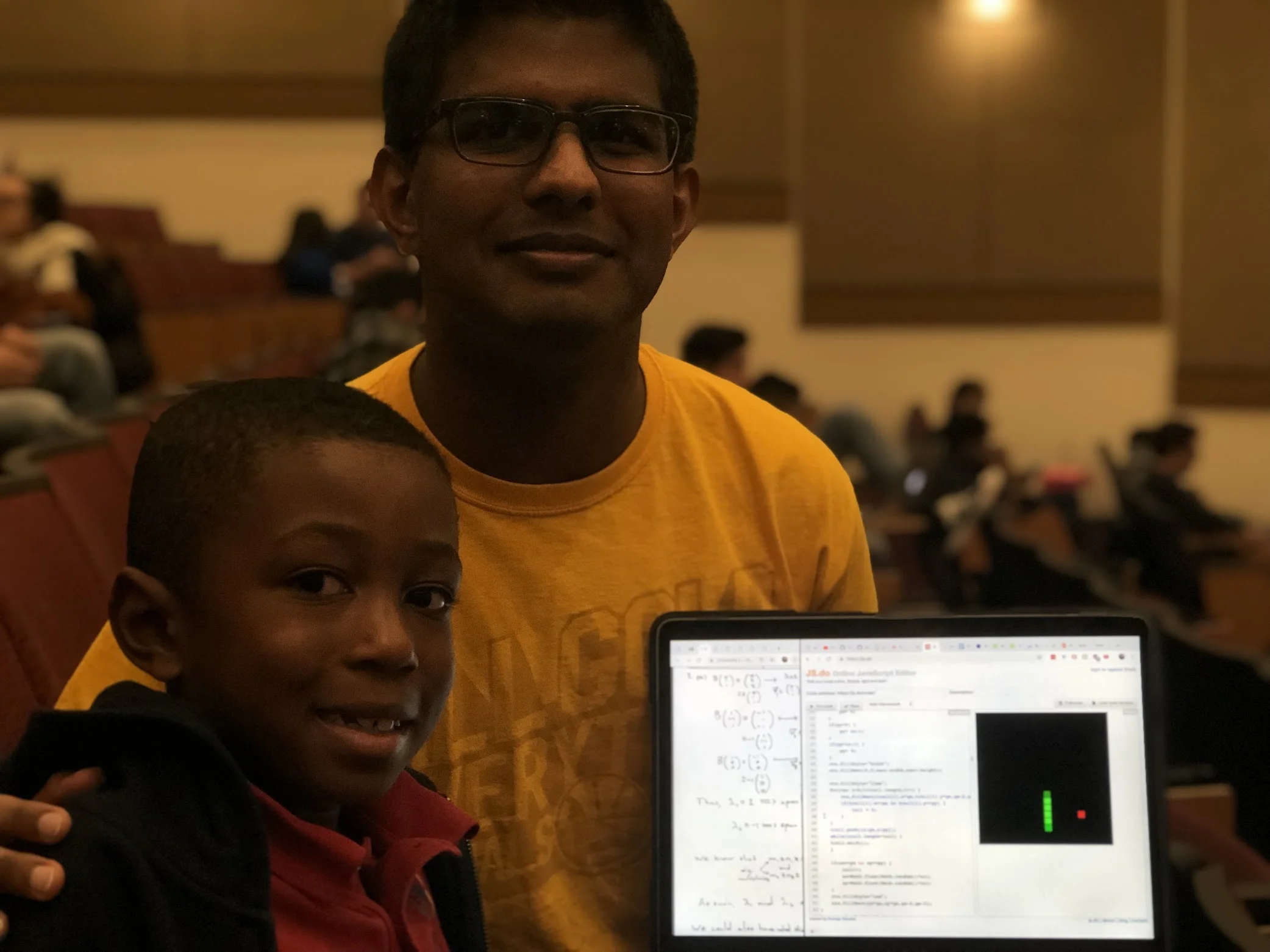
With finals season in fall swing a couple friends and I took a couple hours off today to do an hour of code with K-12 kids from South Central Los Angeles. I was paired up with an elementary schooler named Hunter, and we were supposed to be spending the evening working on an ipad doing some really basic programming on ScratchJr.

Now while Scratch Jr. does have a pretty intuitive interface, it ended up boring Hunter within a couple minutes. He even asked me why I would code on Scratch Jr. all day since it seemed really boring.
Seeing that I was losing him on the Scratch Jr, I decided to pivot and show him some of the projects I’ve been working on. We started off with a hangman game I had made in Java which utilized multi-threading and networking. I explained how all the games he played on his I-pad which were multiplayer used a similar set up - in a water down elementary school level way of course.
After seeing his excitement I then asked him if there were any games he liked playing. He said he really liked the game “snake.” So we spent a decent amount of time building the game in javascript.

The game of snake I coded with Hunter
After coding up the game of snake, and him going around the room showing it off to his friends. He asked me if we could create the game “Pong,” he had heard his dad talk about. So we went off and after a couple of google searches and keystrokes we had a working version of Pong going.

We made sure to have the ball colored in Cardinal and Gold, because GO USC colors!
After building out Pong, he asked me how he could build a game that would give him different recipes to help his mom out in the kitchen. So I got started working on my Virtual Machine, walking through the steps to code a recipe bot in C++ that could get recipes from a recipe API. We only got a couple minutes to work on it though, before Hunter had to go home (so its a project for another day for him)
But more importantly I had a lot of fun talking about what a CS student. Now while I seriously doubt Hunter will be able to program like a “hacker” as he calls it by tomorrow. I think that working through the projects with him, showed him how cool it is to be a CS major. When I first asked him what he wanted to be when he grew up he said a policeman for the LAPD. After the evening coding with him he now wants to be a "cyber policeman" for the NSA.
Imperfect Forward Secrecy: How Diffie-Hellman Fails in Practice
Link: https://weakdh.org/imperfect-forward-secrecy-ccs15.pdf
Summary:
This paper looks at the popular Diffie-Hellman key exchange protocol and find that it is less secure than most people assume it to be. This lack of security to the researcher's credit is a TLS protocol flaw rather than a vulnerability meaning that it is at the core of the protocol and cannot be easily patched overnight. The study figures that modern security standards should be above the 1024 bit standard that can reasonably be cracked by the national security agency and other nation states. The paper goes so far as to even pull up leaked NSA diagrams detailing how the agency might have possibly used a similar method in order to decrypt VPN traffic in a passive manner.
What I liked:
The paper is really pertinent given its widespread use and the NSA disclosures post Snowden
The paper does a good job of explaining the process - I especially liked the visual diagram which put a picture in my head
The attack focuses on an inherent flaw in the protocol compared to a quick patch which makes the paper more impressive
The level of collaboration between all the different authors. This is probably the most diverse group of researchers that I've seen reading papers this year.
I like how the paper specifically went into the breakdown of which percentage of servers are vulnerable ie 82% apache 10% ssl etc
What I didn't like:
The paper focuses a lot on nation state level attacks, I don't think its possible to really defend against a nation state
It would have been interesting to compare servers by company, and see if Akamai or Cisco or whatever company is more vulnerable and why. But the paper didn't really dig too much into this
The paper never really conceptualized the scale of the attack in terms of user traffic only saying like 7% of 1000000 top trafficked websites instead of 1.2 million users a day which I think is a worst way to describe the scale of the problem
I think it was useless going into the NSA documents, there a lot of different ways they could have broken into the VPN networks
I think a major flaw of this study is that it completely neglects a Diffie-Hellman exchange over elliptic curve groups, which are a lot more secure to these types of attacks
I really would have liked the paper to go more into the optimization techniques to find a more efficient way to reduce the time it takes to do this attack -- I think that's where the academic value of this paper lies
Points for Discussion:
What might be an alternative short term fix in order to keep the current networking methods? Moving over to different cypher suites?
When is the industry planning to update to the new standard of 2048 bits?
Under the assumptions made in this paper -- for how long could the NSA have been passively listening into VPN networks
What defines an academic team that is able to break 768 bit groups - computing powers? How's this different from the enthusiast hacker out there?
How hard would it be to patch the 512 bit group vulnerability caused by the flaw in TLS?
New Ideas:
Explore possible cases where this attack may have been implemented by nation states? Are there any symptoms this type of attack gives off?
Study the rollout of past internet protocols and their subsequent adoption
Make a better data visualization of how many users are vulnerable to this type of attack in order to get a better view of the issue
How does this vulnerability affect specific industry - we can see which industries are more proactive about these types of attacks
Explore the possible economic impacts in monetary terms in a cost benefit analysis for a possible attacker. What type of data will they steal, how much is it worth to them if they sold it
The Matter of Heartbleed
Link: https://jhalderm.com/pub/papers/heartbleed-imc14.pdf
Summary:
This paper was more of a summary of knowledge on the heartbleed attack a vulnerability that was found by Google researcher Neel Mehta in March of 2014. Essentially the attack takes advantage of something known as a Heartbeat Extension which allows either end point of a TLS connection to detect whether its peer is still present. The heartbeat is essentially set from one peer to another, and on reciept of a heartbeat message the peer is supposed to respond back with a similar heartbeat message confirming it is still there. The attack took advantage of this and as a result this paper studied the immediate response and response in the weeks after this was disclosed to the world.
What I liked:
The study didn't only look at who made initial responses to Heartbleed but also found that a surprisingly low number of sites (25%) ended up replacing certificates
I really liked the paper's explanation of what heartbeat was, and its original purpose -- they did a good job explaining its use as a positive and then transitioning into how it could be exploited
Good job explaining why it took so long to update servers, they specifically note that this isn't something that you can patch with a configuration file but instead need to recompile openssl with a flag which is harder to do
They use a lot of different sources that kind of paint a picture of what was going on in the time, their use of many sources gives us a lot of data from different views
I liked the use of visuals specifically the graphs that highlight the days of disclosure vs percentage of patches out on the internet
I thought the inclusion of the notification study and follow up with network operators was probably the most helpful piece of the study.
What I did not like:
I think the paper was more of a SOK then adding anything new to the community
I think the way they estimate who was vulnerable to Heartbleed prior to disclosure needs more work. They currently estimate that 24%-55% of servers were vulnerable but don't go into huge specific how they got that number or explain why there's such a huge variation
I would have wanted more specifics about sites and their industry to see which industries are the ones on top of security and which ones are lagging
I don't like that they took a stance on whether or not this bug was exploited prior to disclosure -- I think that they don't really state what they are looking for so its kind of like chasing a ghost
I think the methodology of how they scanned for which servers were vulnerable wasn't really the best given the high amount of false positives the method gives -- would a survey of operators been better?
Points for Discussion
Why are bugs found at the same time. A private cyber firm found the heartbleed bug about the same time as Neel Mehta at google? Same thing happened at Intel? Is this because of leaks or because of coincidence.
Was there a faster way to deliver patches to the general public
Was there enough of a lead time on Heartbleed for major websites to be expected to have a valid fix.
Were the sources the paper used accurate given that they came from so many different sources. As a result the data could have been measured differently
Are there leaks of this in the snowden papers or did this catch the NSA by surprise as well?
New Ideas:
Study why and how different the estimates were for servers affected by heartbleed. Dig into why there is such a big variation
Look into creating a measure of how easy something is to exploit. Ie hacker vs nation state capabilities because the paper notes that the bug is easy to exploit, but easy is subjective
Explore how responsible disclosure might have prevented more attacks especially on something as widespread as heartbleed.
Explore how public knowledge sped or slowed down the patching of major websites
Is there a way this patch could have been done without recompiling the entire server with a specific flag? This could have sped up patching
Foreshadow: Extracting the Keys to the Intel SGX Kingdom
Link: https://www.usenix.org/system/files/conference/usenixsecurity18/sec18-van_bulck.pdf
Summary:
This paper focused on an alternative method to exploit the SGX secure hardware that comes standard in all intel chips post 2013. This paper takes advantage of speculative execution, a protocol in which commands are executed out of order. This causes indirect access to memory for users who should not have this access. Once this mistake happens there are a number of ways that this can be used to extract data from the secret, going so far as to actually get cryptographic key information. More importantly though is the fact that a lot of these vulnerabilities are build into the micro-architecture of the chips so they are extremely hard to patch. This paper has me wondering though how the researchers came across this topic, especially with two similar papers being published during the embargo period within weeks of each other.
What I liked:
The paper is very topical with the intel SGX vulnerabilities recently
The paper is a very general attack that doesn't go into basic assumptions that need to be in the system.
The paper's attack mechanism doesn't require root access - which kind of prevents it from being able to defend against internal attacks ie when the admin is malicious - also the fact the researchers were able to extract full cryptographically keys
I liked the fact they gave a really good example of when this problem might be used in cloud attacks ie "co-residing cloud tenants" could be attack vectors which is something I didn't even imagine
The paper was very weak on mitigation techniques for Intel, but like that kind of proves how good their attack plan was
What I didn't like:
The paper was released concurrently with the patches - I think that might have been a little bit too soon
The paper didn't go into enough depth on the breaking the SGX sealing and attestation. It left me with the questions regarding the security behind the sealing
The paper kind of jumps in with the idea that everyone knows what speculative execution is - given this is a fairly new concern I'd like it if they explained it out more
I wish they published more in depth details about how they were able to execute an attack like this - like it would be amazing in the real world if they posted code but given the magnitude of the vulnerability I understand why they may not have
This paper could have used a lot more visuals, especially when explaining more about the very dry aspects of caches and how their approach compromises the safeguards that are currently in place
Points of Discussion:
How has the response from large cloud service providers who use SGX (ie Microsoft and IBM) deferred from their smaller startups?
How do Block Chains rely on this secure hardware specifically?
Is the debug enclaves in the production version systems in every computer or are they specific to ones Intel had during testing
How did researchers stumble on to this type of vulnerability?
Has the proprietary nature of Intel's chips helped or hurt the security of its systems.
New Ideas:
Explore how the attestation is arbitrary if Intel has a centralized service for it
Map out the current systems currently in use that haven't been patched for these bugs
Would slowing down the CPU speeds prevent speculative execution? To what degree and how would this compare to current mitigation techniques
How might Intel need to change the micro-architecture of future chips in order to prevent against similar attacks in the future
Is there an approach that can fix the vulnerabilities in architecture over the air ?